Spring Data JPA Hibernate String Primary Key Example
- Details
- Written by Nam Ha Minh
- Last Updated on 08 November 2022 | Print Email
In Spring Data JPA with Hibernate, it’s very common of using numeric type for an entity’s ID field that maps to a primary key column in the database table. What about string primary key?
Well, there will be cases in which we need to use text data type for primary key column / ID field instead of numeric type. Read on, as this article will explain why and how with code examples.
1. Why String Primary Key?
We can use string primary key for a column if a text value uniquely identifies a row in the table - no duplicate values are allowed. For example, the email column in users table can be primary key because each user has a unique email address; the code column in countries table can be primary key because no two countries having the same country code.
Using string primary key has the following pros and cons:
Pros: database is simpler as no need a numeric primary key as usual. The code in Spring Data JPA/Hibernate is also simpler. Business requirements can be met easily.
Cons: a value in a string primary key column cannot be updated once it was inserted. It may cause the code inflexible.
2. String Primary Key Example with Spring Data JPA/Hibernate
To declare a String ID field in an entity class, simply annotate the field with @Id annotation but not @GeneratedValue as values in string primary key column cannot be auto generated. Below is an example:
package net.codejava.user;
import javax.persistence.*;
@Entity
@Table(name = "users")
public class User {
@Id @Column(length = 50)
private String email;
@Column(nullable = false, length = 40)
private String name;
private boolean enabled;
// getters and setters are not shown
}Here, the email field maps to a string primary key column in the users table:
@Id @Column(length = 50) private String email;
In MySQL Workbench, the table structure would look like this:
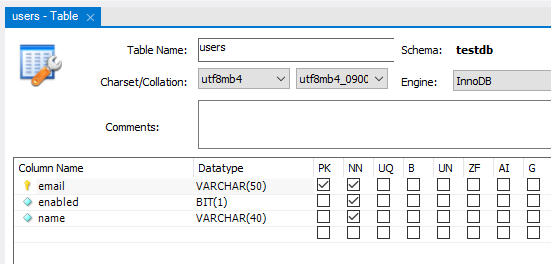
Then, in the corresponding repository interface, you also need to specify the type of ID field is String:
package net.codejava.user;
import org.springframework.data.repository.CrudRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface UserRepository extends CrudRepository<User, String> {
}And unlike Integer ID field, you need to specify value for the String ID field when persisting a new object. For example:
User newUser = new User();
newUser.setEmail("nam@codejava.net");
newUser.setName("Nam Ha Minh");
repository.save(newUser);That also means, for find by ID operation, the type of ID is now String. For example:
String email ="nam@codejava.net"; Optional<User> findById = repo.findById(email);
That’s how to use String primary key column / String ID field in Spring Data JPA with Hibernate. I hope you find this post and code example helpful. You can also watch the following video to see the coding in action:
Related Spring and Database Tutorials:
- Spring Data JPA EntityManager Examples (CRUD Operations)
- JPA EntityManager: Understand Differences between Persist and Merge
- Understand Spring Data JPA with Simple Example
- Spring Data JPA Custom Repository Example
- Spring MVC with JdbcTemplate Example
- How to configure Spring MVC JdbcTemplate with JNDI Data Source in Tomcat
- Spring and Hibernate Integration Tutorial (XML Configuration)
- Spring MVC + Spring Data JPA + Hibernate - CRUD Example
About the Author:
 Nam Ha Minh is certified Java programmer (SCJP and SCWCD). He began programming with Java back in the days of Java 1.4 and has been passionate about it ever since. You can connect with him on Facebook and watch his Java videos on YouTube.
Nam Ha Minh is certified Java programmer (SCJP and SCWCD). He began programming with Java back in the days of Java 1.4 and has been passionate about it ever since. You can connect with him on Facebook and watch his Java videos on YouTube.
Comments
Thanks. The method findById works great even when the primary key is not an integer..